You only look once (YOLO) -- (2)
 Vehicle Detection Result
Vehicle Detection ResultYOLO has higher localization errors and the recall (measure how good to locate all objects) is lower, compared to SSD. YOLOv2 is the second version of the YOLO with the objective of improving the accuracy significantly while making it faster.
The backbone network architecture of YOLO v2 is as follows: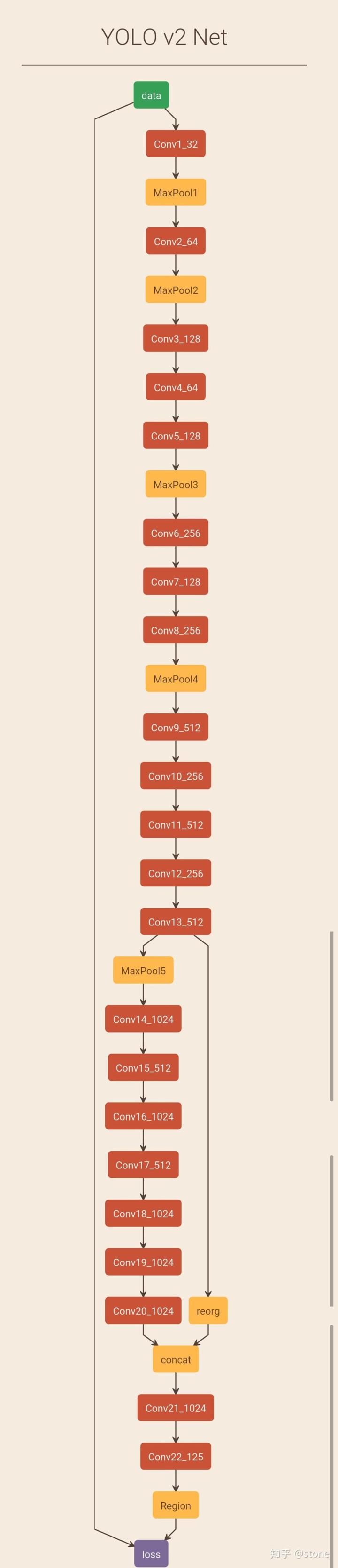
1. Accuracy Improvements
Batch Normalization
Also removes the need of dropouts. mAP increases by 2%.
High-resolution Classifier
To generate predictions with shape of $7\times 7 \times 125$, we replace the final fully connected layers with a $3\times 3$ convolution layer each outputting 1024 output channels. Then we apply a final $1\times 1$ convolutional layer to convert the $7\times 7 \times 1024$ output into $7\times 7 \times 125$ and retrain it end-to-end. This makes training easier and moves mAP up by 4%.
Convolution with Anchor Boxes
Early training is susceptible to unstable gradients. Arbitrary guesses on the boundary boxes may result in steep gradient changes.
In real life, boudnary boxes are not arbitrary. So the author create 5 anchor boxes with the following shapes.
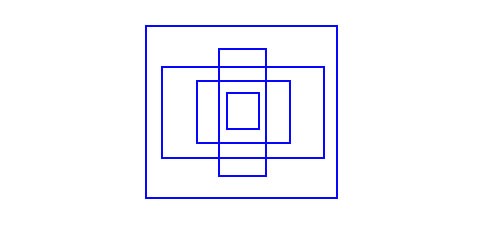
Instead of directly predicting 5 arbitrary boundary boxes, we predict offsdets to each of the anchor boxes. If we constrain the offset values, we can maintain the diversity of the predictions and have each prediction focusing on specific shape. So the initial training will be more stable.
Dimension Clusters
In many problem domains, the boundary boxes have strong patterns. For example, in the autonomous driving, the 2 most common boundary boxes will be cars and pedestrians at different distances. To identify the top-K boundary boxes that have the best coverage for the training data, we run K-means clustering on the training data to locate the centroids of the top-K clusters.
Since we are dealing with boundary boxes rather than points, we cannot use the regular spatial distance to measure datapoint distances. No surprise, we use IoU.
Direct location prediction
We make predictions on the offsets to the anchors. Nevertheless, if it is unconstrained, our guesses will be randomized again. YOLO predicts 5 parameters (tx, ty, tw, th, and to) and applies the sigma function to constraint its possible offset range.
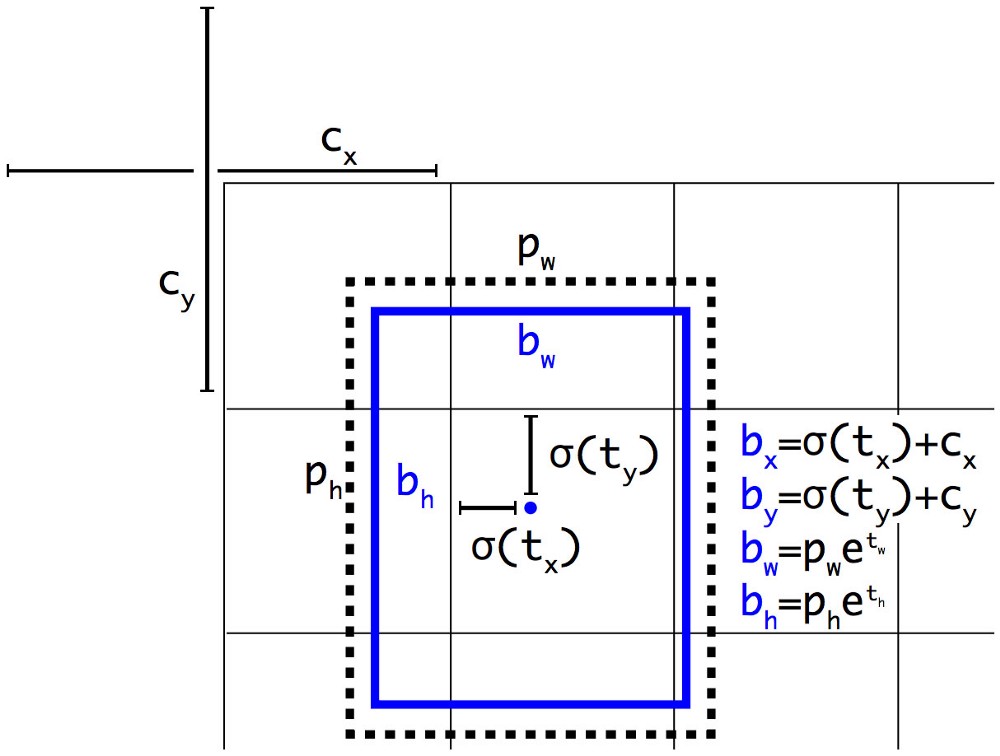
With the use of k-means clustering (dimension clusters) and the improvement mentioned in this section, mAP increases 5%.